Molecules 2022, 27(5), 1639
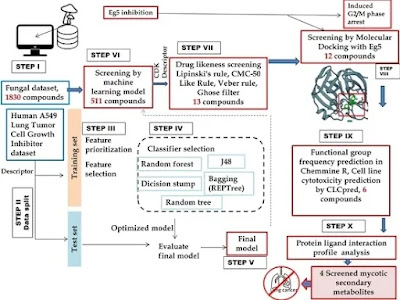
Among the various types of cancer, lung cancer is the second most-diagnosed cancer worldwide. The kinesin spindle protein, Eg5, is a vital protein behind bipolar mitotic spindle establishment and maintenance during mitosis. Eg5 has been reported to contribute to cancer cell migration and angiogenesis impairment and has no role in resting, non-dividing cells. Thus, it could be considered as a vital target against several cancers, such as renal cancer, lung cancer, urothelial carcinoma, prostate cancer, squamous cell carcinoma, etc. In recent years, fungal secondary metabolites from the Indian Himalayan Region (IHR) have been identified as an important lead source in the drug development pipeline. Therefore, the present study aims to identify potential mycotic secondary metabolites against the Eg5 protein by applying integrated machine learning, chemoinformatics based in silico-screening methods and molecular dynamic simulation targeting lung cancer. Initially, a library of 1830 mycotic secondary metabolites was screened by a predictive machine-learning model developed based on the random forest algorithm with high sensitivity (1) and an ROC area of 0.99. Further, 319 out of 1830 compounds screened with active potential by the model were evaluated for their drug-likeness properties by applying four filters simultaneously, viz., Lipinski’s rule, CMC-50 like rule, Veber rule, and Ghose filter. A total of 13 compounds passed from all the above filters were considered for molecular docking, functional group analysis, and cell line cytotoxicity prediction. Finally, four hit mycotic secondary metabolites found in fungi from the IHR were screened viz., (−)-Cochlactone-A, Phelligridin C, Sterenin E, and Cyathusal A. All compounds have efficient binding potential with Eg5, containing functional groups like aromatic rings, rings, carboxylic acid esters, and carbonyl and with cell line cytotoxicity against lung cancer cell lines, namely, MCF-7, NCI-H226, NCI-H522, A549, and NCI H187. Further, the molecular dynamics simulation study confirms the docked complex rigidity and stability by exploring root mean square deviations, root mean square fluctuations, and radius of gyration analysis from 100 ns simulation trajectories. The screened compounds could be used further to develop effective drugs against lung and other types of cancer.